ながーい前フリ
研究室の簡単な紹介ページを作って公開しています。大学の(少なくとも理系の)研究室ってこういうことするのがデフォルトだと思っていました。でもあまりやる人って多くないんですよね。自分の当たり前は他人の当たり前ではない。そういうことです。
昔はグローバルIPがあったので研究室にWebサーバを立ててHTML直書きしたりPukiwiki使ったりWordPressを使ったりしてきました。一方、研究室でWebサーバを立てるのはセキュリティ的に問題になることがありまして、その後、色々と試行錯誤してここ5年くらいはGoogle Sitesに落ち着いています。
以前は授業資料などもそこで公開していたのですがコロナ以降はGoogle Classroomを使うようになったため、ホームページは単に学生さんの研究一覧と研究室で関わったプロジェクトのリンク置き場になっていました(あと非常勤用の授業ページですね)。
このままでも全く不都合はないのですがなんだか楽し過ぎだな。。。と思っていました。Notion使う手もあるんでしょうけどそれもね。。。せっかくなのでGitHub Pagesにホームページを移すことにしました。Markdownで書いてそのまま公開することもできそうです。
ちょっとした問題
Google SitesのページをMarkdownにするため、ページを開いてテキストを全選択してREADME.mdにコピペしてMarkdownの装飾を加えていく単純な作業でした。ただ、このページにはYouTubeのリンクが含まれているため単純にWebページをコピペしてもリンクはコピーされないため。。。これを移すのは面倒と思いました。右クリックしてリンクをコピーし、そのアドレスをREADME.mdにペーストする、という作業をひたすらすればいいんでしょうけど、そういう単純作業はコンピュータにやらせるべきですよね。。。ということでプログラミングの出番です。
方法
YouTubeのリンクが含まれているページにアクセスして、そこで右クリックしてページのソースを表示します。その内容をaというファイルにペーストします。別にファイル名はaでなくてもいいですが、あとのスクリプトの説明に合わせるためこのではaとしています。
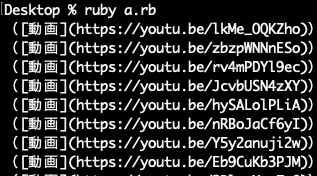
aと同じフォルダにa.rbというファイルを作成し、以下をコピペし、ruby a.rbなどと実行します。すると、Markdown形式でのリンク文字列が表示されます。リンク文字列は「(動画)」としていますが、用途に合わせてその他に変えていただければと思います。
a=File.open("a").read a.scan(/https?:\/\/[\w\/\?\@\-\:\%\.\_\+\~\#\=]*youtu[\w\/\?\@\-\:\%\.\_\+\~\#\=]+/).each do |e| puts "([動画](#{e}))" end
抽出しようとしている文字列の仕様は次の通りです。こちらも別の用途へ転用する場合に参考にしてください。⇒「https://もしくはhttp://」「URLとして使える文字が0文字以上続き」「youtuがあって」「URLとして使える文字が1文字以上続く」です。最後にダブルクォーテーションマークが終端文字になりマッチング完了して次の文字列を探索しに行く感じに動作します。String#scanは指定された正規表現にマッチするすべての文字列を配列として返すメソッドとのことです。今回初めて使いました。便利です。
ちなみに実行結果の例を以下に貼っておきます。
正規表現って面白いですねぇ。