昨日、めでたく!?採点支援ツールを公開したのですが...これがいくつか問題があって。どうしたものかと。
採点支援ツール(ブラウザ版)作りました👍 - memorandums
問題1 解答欄画像が薄い
これは解答画像の縮小にp5.js PImageのresizeを使っているのですがこれが品質が良くない。PILのresizeは何でしょうね?リサンプリングとかしているのでしょうか?綺麗に縮小されるのですが。。。
品質のよいresizeアルゴリズムを載せようとしたのですがJSでのいい実装が見つからず断念しまして、簡単ですが、縮小前にかすれている筆記をより鮮明にするため画像処理のErodeをしてみました(PImageにはfilterメソッドが実装されているので1行追加で処理できました)。いい感じになったのでこれでOKということにしました。
ちなみに例を1つ。以下が採点斬りでも使用しているPILです。

そして、p5.jsが以下。

で、erodeしたのが以下です。OKですよね?

はい次。
問題2 処理中にブラウザが固まりPCの動きが悪くなる
現状は、複数の解答画像(下図は1, 2, 3)をアップロードしたときにファイル名順に処理してExcelに追加していきます。ブラウザでファイルをどう選択してもp5.jsには同時並行で送信されるので、その処理は非同期になります。これを無理やり図にしたのが以下です。
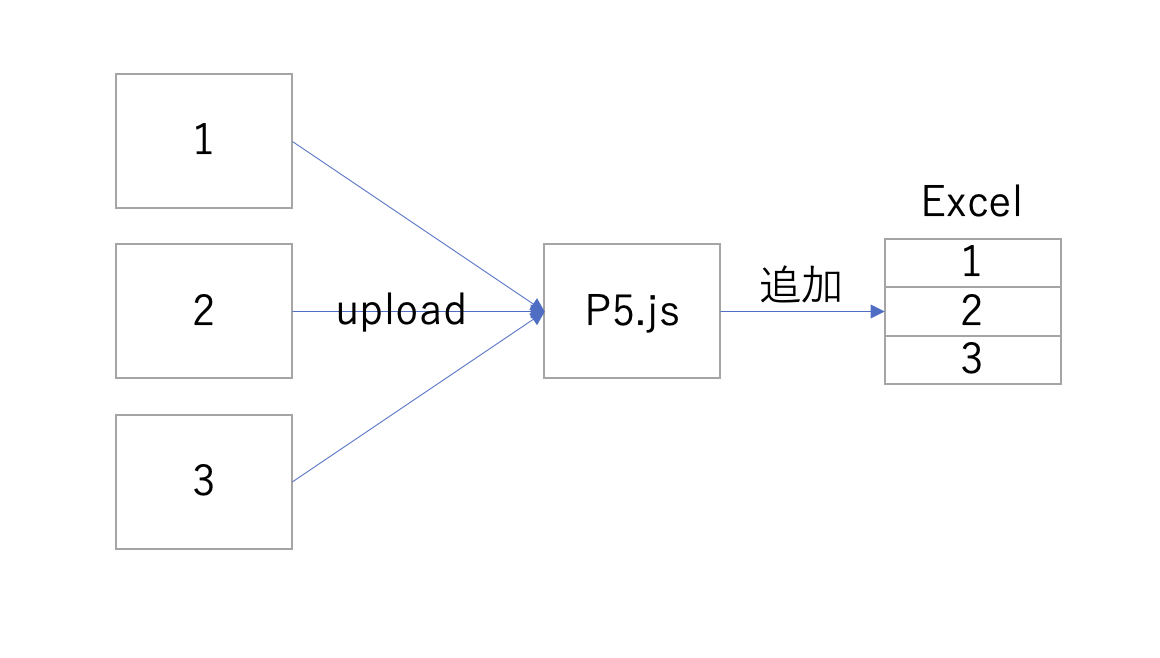
送られてきた図をファイル名でソートするため、一度、全部受け取ってからファイル名でソートして、Excelに追加していました。100近い画像ファイルを全部メモリに読み込むためブラウザ=PCのメモリの残容量が厳しくなるのは容易に想像できます。なるべくしてなっているな。。。と。
対策1 ファイル名で整列してから送信すればいいじゃん。。。(結果、これは無策に等しい)
p5.jsのソースコードがgithubで公開されていますので見てみると以下でした。これだけ書いてもなんのことかと思いますが。。。せっかく今回調べたので自分のために記録しておこうという魂胆です。
ユーザがinputタグで選択した複数ファイルがevent.target.filesに入っています。これを辞書順にソートしてからp5.File._loadを呼べばいいじゃん。。。と単純に思ったんですね。
p5.prototype.createFileInput = function (callback, multiple = false) {
p5._validateParameters('createFileInput', arguments);
const handleFileSelect = function (event) {
for (const file of event.target.files) {
p5.File._load(file, callback);
}
};
で、これを以下のように書き換えました。CSVファイルもアップロードするので、CSVファイルを最初に読み込むように強制的に書き換え、残りは辞書順にソートしてからp5.File._loadを呼ぶようにしましたが。。。これがダメでした。
結果的にExcelにデータを追加するのはcallback関数が呼び出される順番になるので。。。_loadを解答画像のファイル名順に呼んでも何も意味がないことがわかりました。。。だよね。非同期プログラミングって日常的にしているようでしてないことを改めて意識することになります。Webエンジニアはここで戦っているんですね。
p5.prototype.createFileInput2 = function (callback, multiple = false) {
p5._validateParameters('createFileInput', arguments);
const handleFileSelect = function (event) {
let fs = {};
for (const file of event.target.files) {
if (file.name.slice(-4) === '.csv') {
p5.File._load(file, callback); //最初にCSVファイルを呼び出す
} else {
fs[file.name] = file;
}
}
let fnames = Object.keys(fs).sort(); //画像データは辞書順ソート
for (const f of fnames) {
p5.File._load(fs[f], callback);
}
};
対策2 ファイルを読み込むときにタイマー処理すれば呼び出した順番にcallback関数が呼ばれるのでは?
何とか非同期処理を同期させようとやってみましたが妙案が思いつかず、昔ながらのタイマー処理で逃げられないか?でやってみたのが以下です。
タイマー関数としてsleep関数を定義して、async, awaitで定義します。。。これやってみたら、確かにExcel上に辞書順に解答画像が並ぶことを確認できましたが。。。callbackだけでなく受信処理もブロックするようでとても処理が遅くなることがわかりました。
p5.prototype.createFileInput2 = function (callback, multiple = false) {
p5._validateParameters('createFileInput', arguments);
//-----------------------------修正開始
const handleFileSelect = async function (event) {
const sleep = (millisecond) => new Promise(resolve => setTimeout(resolve, millisecond)) //★
let fs = {};
for (const file of event.target.files) {
if (file.name.slice(-4) === '.csv') {
p5.File._load(file, callback); //最初にCSVファイルを呼び出す
} else {
fs[file.name] = file;
}
}
let fnames = Object.keys(fs).sort(); //画像データは辞書順ソート
for (const f of fnames) {
p5.File._load(fs[f], callback);
await sleep(100); //★
}
//-----------------------------修正終了
};
それでも、この処理によってクライアントからブラウザに画像ファイルを読み込むごとに処理できる(あとでまとめて処理しない)ので、メモリが逼迫する状況はなくなりました。
もう、これでいいかな。。。と思って帰路についたのですが。。。やはりsleepとか不確実で無駄なことをしていると思いましたので。。。なんとかしたいな。。。と。
対策3 画像ファイル本体を受信する前にファイル名一覧を取得し辞書順に並べて、ファイル名がどのExcel行位置にくるか計算しておく
ファイルを複数選択したときにファイルリストはinputタグ情報から入手できることがわかりましたので、ファイル一覧を先に作成して辞書順にソートすることで、あとからファイル本体を受信したときのExcelシート上の行位置を予め知ることができそうだとわかりました。これを言葉だけで説明するのは限界がありますし、図説されてもね。。。よくわからないと思います。とりあえずやったことを記録しておきます。
これでsleepすることなく、非同期で送られてくる画像データを受信したときに、それぞれの解答をExcelに貼り付けるときの行位置がわかりましたので、うまくExcelデータを作成することができることがわかりました。
ただ。。。処理自身をみると88名で2分くらい。結構長い。。。
昨日リリースした処理は40秒くらいでした。
対策4 Erodeを止める
遅くしている原因はErodeでした。これをすることで処理時間がかかるようです。
結果的に、Erodeはやめて、学生のスキャン画像を一括で画像処理ツールで変換する(Erode)して与えるようにすればツールでやる必要はなくなり処理時間も40秒くらいになることがわかりました。
ということで、上記の問題2は解決できたと思いますが、問題1は総合的な観点で取りやめし、事前にツールで一括処理するといいな。。。ということにしました。
はい。とりあえずこれで本ツールの問題は大方解消できたと思います。
誰に伝わることもないでしょうけど。。。色々と試行錯誤しつつ判断した結果から今のサービスが成立している感じです。